이번에는 문제 상황에 따라 어떻게 neural network 구조를 설계해야 하는지 살펴본다. 그 이전에 activation function에는 어떤 것들이 있는지 알아본다.
0. Various Activation Funtions
활성화 함수를 사용하면 입력값에 대한 출력값이 non-linear하게 나오므로 선형 시스템을 비선형 시스템으로 만들 수 있다. 따라서 MLP(Multiple layer perceptron)는 단지 linear layer를 여러개 쌓는 개념이 아니고 활성화 함수를 이용한 non-linear 시스템을 여러 layer로 쌓는 개념이다. 다양한 활성화 함수가 존재하는데 하나씩 설명한다.
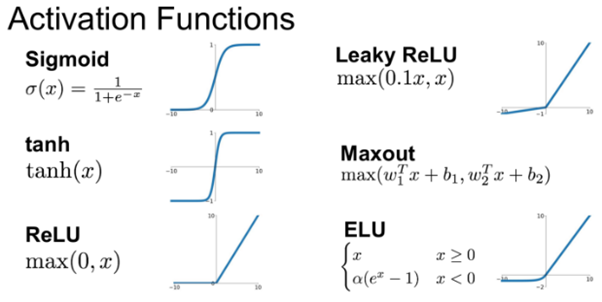
Sigmoid
Activation: $a = \sigma (x) =\frac{1}{1+e^{-x}}$
Gradient: $\frac{\partial a}{\partial x} = \sigma (x) (1- \sigma (x))$
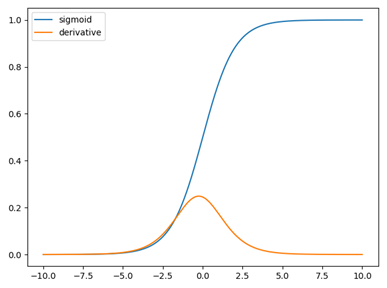
Sigmoid 문제점
- 미분함수는 y값의 범위가 너무 작다.
- 미분함수의 양극단이 0에 수렴하여 미분해도 업데이트가 잘 되지 않는다.
- 미분값이 모두 양수이며 zero-centered 되어 있지 한다.
- 미분값이 항상 양수라서 강도만 있을뿐 방향을 바꾸지 못한다.
- 미분값이 1보다 작아서 gradient가 너무 작다.
Tanh
Activation: $a = tnah(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}} $
Gradient: $\frac{\partial a}{\partial x} = 1- tanh^2(x)$
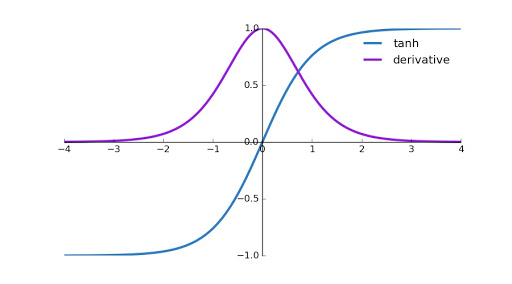
Tanh 장점
- tanh는 [-1,+1] 사이의 값을 가지므로 zero-centered 되어 있다.
- 음수값도 가져 방향성을 바꾸기가 가능하다.
Tanh 단점
- 미분함수의 양극단이 0에 수렴한다.
- 미분값이 0 근처에서 포화상태이다.
- 미분값이 1보다 작아서 gradient가 너무 작다.
Linear
Activation: $a = \theta (x)$
Gradient: $\frac{\partial a}{\partial \theta} = x$

Linear 장점
- 미분값이 0에 가깝지는 않다.
- 안정적인 gradient를 가진다.
- 포화되는 구간이 없다.
Linear 단점
- 양수와 음수인 경우를 구분하지 못한다.
Softmax
Activation: 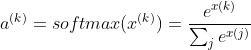 $\sum_{k=1}^{K} a^{k} = 1$ for K classes
$\sum_{k=1}^{K} a^{k} = 1$ for K classes
ReLU
Activation: $a = h(x) = max(0,x)$
Gradient: 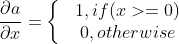
ReLU 장점
- 양극단이 포화되지 안는다.
- 계산이 효율적이다.
- 수렴속도가 빠르다.
- 구분적 선형함수이기 때문에 안정적이다.
ReLU 단점
- 중심값이 0이 아니다.
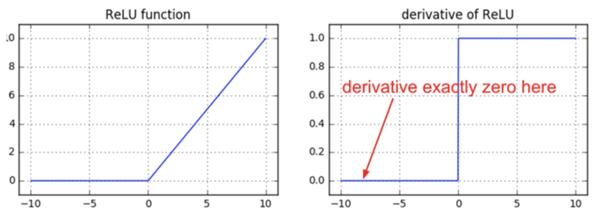
- 입력값이 음수인 경우 미분값이 0이라서 업데이트되지 않는다. (dead neuron이 생긴다.) -> Leaky ReLU로 극복
- 비연속함수라서 미분불가능한 검이 생긴다. -> softplus로 극복
Leaky ReLU
Activation: 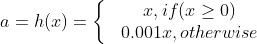
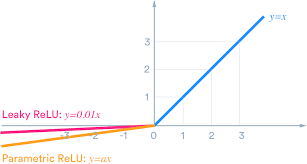
Leaky ReLU 장점
- 음수값에 대한 미분값이 0이 되지 않는다.
Parametric ReLU
Activation: 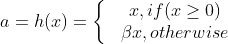
Parametric ReLU 장점
- x < 0 에서 기울기를 학습할 수 있게 한다.
ELU
Activation: 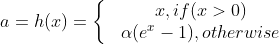
Gradient: 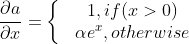
ELU 장점
- ReLU의 모든 장점을 포함한다.
- zero-centered에 가깝다.
ELU 단점
- exp 계산이 힘들다.
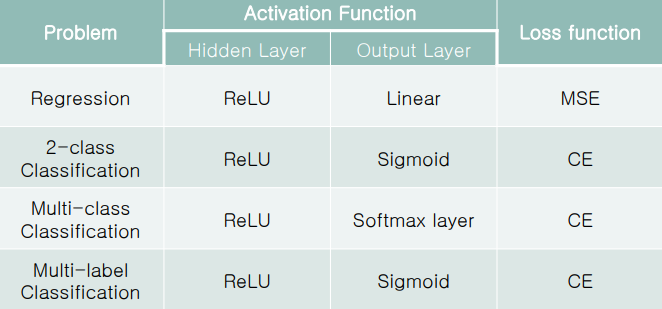
1. Regression
Regression은 회귀모델로 input 값을 가지고 real number를 output으로 낸다. Regression은 가질 수 있는 값의 범위가 엄청 넓기 때문에 output layer는 activation 함수를 사용하지 않고 summation 값을 그냥 출력한다. 이는 activation function으로 $y=net$(linear function)을 사용한다고 봐도 된다. 여기서 주의할 점은 output layer의 activation function만 $y=net$을 사용하는 것이지 hidden layer의 activation function을 $y=net$로 하면 안된다. NN의 non-linear transformation이 무너지기 때문이다. 이는 굳이 NN을 multilayer로 가져갈 필요가 없다는 의미이기도 하다.
Regression의 경우는 output layer를 non-linear transformation의 목적으로 사용하는 것이 아니라 non-linear transform된 값들을 가지고 최종 결과를 얻어내는, 다시 말해 임의의 범위 안의 값들을 얻어내기 위해서만 사용한다.
정리하면 regression을 하려면 output layer에 linear activation을 사용하거나 activation function을 사용하지 않아도 된다.
2. Binary-class Classification

classification에서 우리가 얻고 싶은 정보는 숫자가 아닌 class 값(nominal values:이름값)이다. 여기서 첫 번째 문제는 NN은 real number만 다룰수 있다는 것, 두 번째 문제는 error function으로 MSE를 사용해서 학습시켜도 되는지 이다.
Handling nominal value
Binary class이므로 calss값을 0과 1로 바꾸고 학습시키면 된다. 그리고 output layer의 activation function은 sigmoid를 사용하면 된다. Sigmoid 함수는 한 쪽 극단이 1이고 한쪽 극단이 0의 값을 가지기 때문이다.
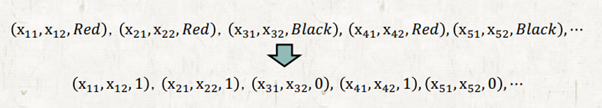
Error function for traning
정답부터 말하면 cross entropy 함수를 사용하면 된다. Sigmoid 활성화 함수와 MSE error function을 함께 사용하는 것은 사용하지 않는게 좋다. 이론상으로는 학습이 잘 될것 같지만 그렇지 않은 경우가 생기기 때문이다.
예를 들어 1이 출력으로 나와야 되는데 예측값이 0인 경우 gradient가 0이 되어 학습이 일어나지 않는다. 다시말해 NN 이 정답을 완전히 반대로 알고 있는 경우 학습이 아예 되지 않는다.
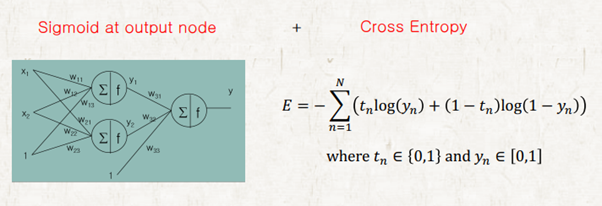
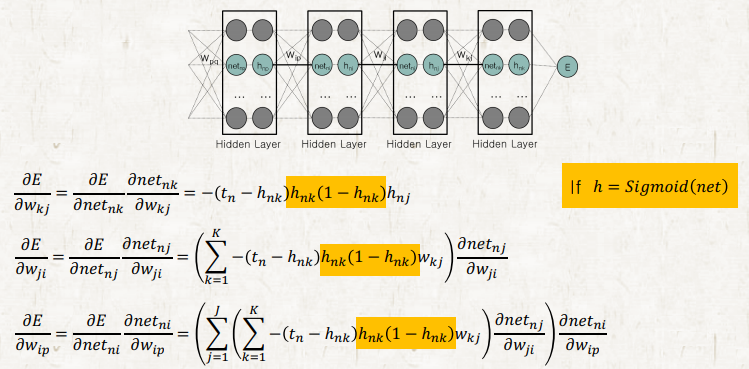
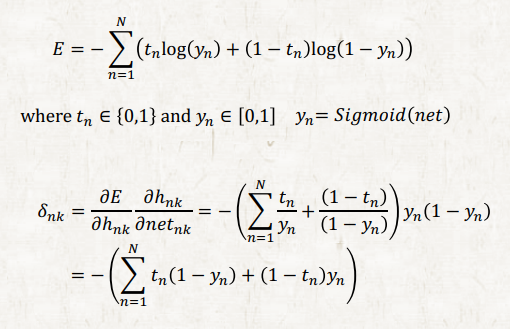
같은 상황에서 cross entropy activation function을 사용하면 gradient가 0이 되지 않아 학습이 가능하다. Cross entropy loss는 가장 유명한 classification을 위해 사용되는 loss로 softmax와 sigmoid activation 함수와 주로 같이 사용된다. 그 이유는 CE는 softmax와 sigmoid의 exp을 없애준다.
3. Multi-class Classification
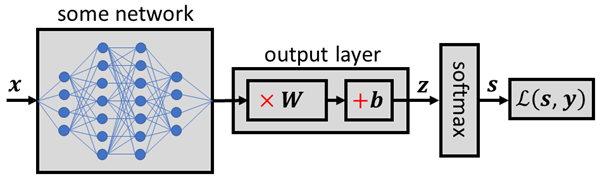
출처: https://towardsdatascience.com/derivative-of-the-softmax-function-and-the-categorical-cross-entropy-loss-ffceefc081d1
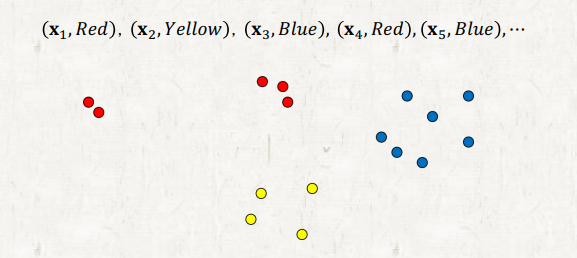
Handling nominal value
Binary-class Classification처럼 각 class label(nominal value)을 linear하게 숫자로 mapping 하면 된다.
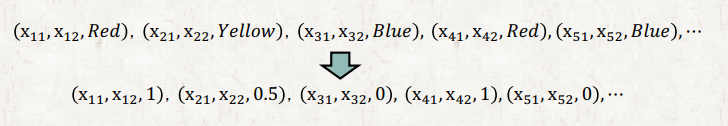
하지만 이는 문제가 있다. 우리는 Red > Yellow > Blue 라고 할 수도 없을 뿐더러 Red를 Yellow라고 해서 틀리는 경우와 Red를 Blue라고 해서 틀리는 경우 둘다 똑같이 틀린 경우지만 수식으로 계산하면 error 값이 달라지기 때문이다. 차라리 틀릴거면 Yellow라고 해서 틀리는 게 낫다는 암묵적인 지시가 포함된 문제로 바뀌어 본질이 달라진다는 것이다.
이를 해결하기 위해 virtual output을 만들어 준다. 실제로는 출력이 하나밖에 없지만 one-hot encoding으로 출력을 세 개로 쪼개준다. 즉, NN의 output의 개수는 class의 개수와 동일하다. 각 output의 cross entropy 값을 더해서 loss로 활용하면 된다.

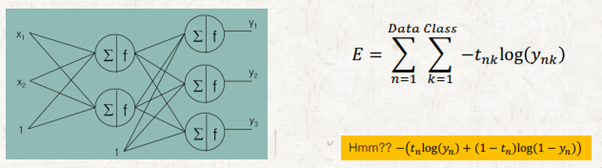
Binary Class Cross Entropy vs Multi-Class Cross Entropy
여기서 binary-class할 때랑 수식이 다른데 라는 의문을 품을 수 있다. 하지만 표현만 다를 뿐이지 결과 값은 동일하다.
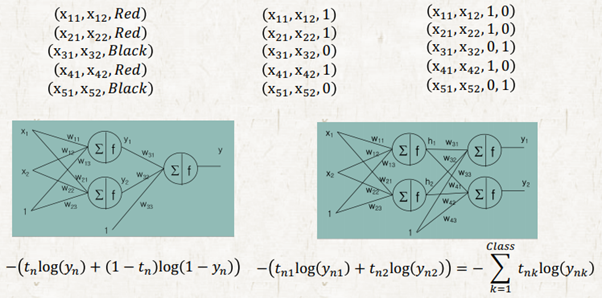
Activation function for traning
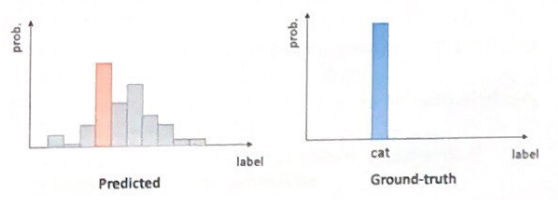
Output layer의 activation function 으로는 sigmoid 대신 softmax 함수를 사용한다. 그 이유는 multi-class classification의 모든 output 값을 더하면 1이 되어야 하는데 sigmoid는 이를 만족하지 못하기 때문이다. 따라서 이를 만족할 수 있는 softmax 함수를 사용한다. Softmax 함수는 사실상 activation function보다 layer로 보면 편하다.
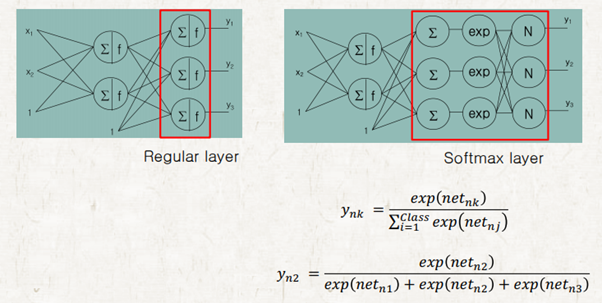
Softmax layer는 summation을 한 후 exp를 통과한 결과를 normalize 하여 모든 노드들의 출력값의 합을 1이 되도록 만든다. exp 없이 normalization해도 상관없지만 exp를 쓰면 수학적인 성질이 좋아지기 때문에 exp를 사용한다.
Error function for traning
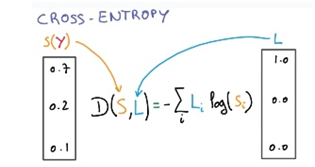
cross entropy 함수를 사용하면 된다. softmax layer를 거치더라도 output은 0~1 사이의 값이 나오기 때문에 그대로 cross entropy loss를 사용한다.
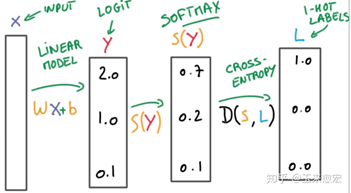
정리하면 softmax 함수로 output으로 나온 값들의 합이 1이 되도록 변경해준 후에 one-hot vector로 변경실제 label과 비교하여 cross entropy loss를 계산한다.
4. Multi-label Classification
Multi-class Classification는 여러개의 변수들에 대해 하나의 output이 있는 것이고, Multi-label Classification은 여러개의 변수들에 대해 여러개의 output이 있는 것이다.
위에서 했던 것을 생각해보면 Multi-class Classification에서 one-hot encoding을 사용해 output을 여러개로 쪼갰다. 이는 Multi-label Classification과 비슷한 형식이 된다고 생각할 수 있다. 하지만 가장 큰 차이점은 Multi-class Classification은 output 값들의 합이 1이 되었다면, Multi-label Classification은 output 값들의 합이 1이 되지 않는다. Label들이 서로 독립이기 때문이다. 따라서 더 풀기 간단한 문제가 되고 output layer에는 sigmoid activation function을 사용한다.
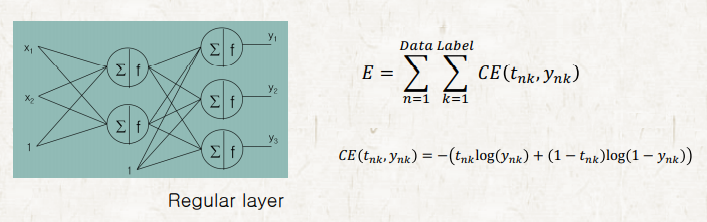
5. Nominal Input
지금까지 nominal value가 output에 나오는 경우만 생각했지만, input으로 nominal value가 들어올 수도 있다.


같은 방식으로 input을 one-hot encoding해서 바꿔주면 된다.
정리